Design Authority at the Speed of decisions.
A perspective on what changes when architecture review moves from quarterly to per-commit, written after building a working multi-agent design authority panel.
Most regulated organisations of any size have a design authority. The constitution varies. Some are formal architecture review boards with quarterly meetings and recorded minutes. Some are technical leadership groups that convene when a vendor decision crosses a threshold. Some are individuals who hold institutional veto and get pulled in late, often too late. The shape is different. The intent is the same. There is a body in the organisation whose job is to ask “should we be doing this” before significant technical decisions are committed to.
The design authority is the right idea. It is also, in almost every organisation I have worked with, operationally broken.
This is a perspective on why, and on what changes when the friction is removed. It is informed by a working prototype I built over the winter – a multi-agent panel that takes an architecture decision record or a GitHub repository and produces a structured ruling in under sixty seconds. The prototype is called Architecture Council. The code is on GitHub. The substance of the piece is not the tool. The substance is what becomes possible when the cost of authority review falls by three orders of magnitude.
Authority review was never free.
Design authority boards are built around an implicit assumption: that authority review is expensive, so it must be rationed. The decisions worth reviewing are the big ones. New platforms. Significant procurements. Cross-cutting standards. Vendor changes with strategic implications. Authority members are senior, their time is scarce, the convening cost is real. So the scope is narrowed to what is worth their time.
The consequence is that the vast majority of architecture decisions in any organisation are made without authority review at all. The choice to add a Redis cache. The choice to introduce a new background job framework. The choice to bring in a library that nobody on the team has used before. The choice to write a service in Python rather than TypeScript because that is what one engineer prefers. Each of these is small. None of them justifies convening a board. All of them, over a year, compound into the architecture the organisation actually has, regardless of what the architecture the organisation thinks it has.
The friction does not just delay authority review. It selects for which decisions get reviewed at all. The big decisions get the structured scrutiny. The thousand small decisions that determine whether the system is actually maintainable in five years get nothing.
This is the operational failure mode. The board does what boards do, well. The system around the board misses everything else.
A panel in sixty seconds.
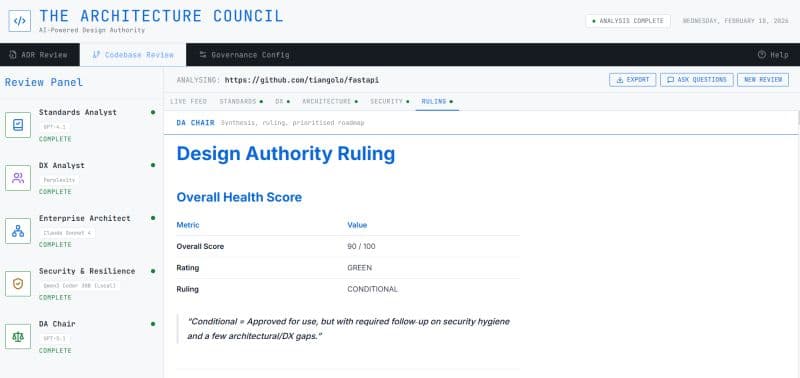
Architecture Council is a working multi-agent panel that runs against either an architecture decision record (the kind you might write before adding the Redis cache) or a GitHub repository (the kind you might point it at to evaluate a vendor's claim or an internal codebase). It produces a structured ruling: approved, conditional, rejected, or deferred, with scored findings against four dimensions and a synthesising chair's summary.
The panel has five members. Each is a different specialist role. Four of them run on different large language models, chosen deliberately for what each model does best. The Standards Analyst and the Chair run on GPT-4.1 for reliable structured output. The Enterprise Architect runs on Claude Sonnet 4 for deeper reasoning on coupling and integration. The Developer Experience Analyst and the Security Analyst run on Perplexity Sonar Pro because both roles need live web data – current CVE feeds, current library health signals, current community state. Using one model for everything would have been simpler. It would also have been worse.
The four specialists evaluate in parallel. The Chair synthesises with weighted scoring. The whole thing streams back over a server-sent events connection while the user watches, agent by agent, in roughly forty-five to sixty seconds. The output is a markdown report the user can export. For a codebase review, it is also a prioritised improvement roadmap.
That is the system. It is roughly three thousand lines of Python on the backend, a Next.js frontend, and a docker-compose for production deployment. The architectural choices that matter are not in the line count. They are in the role definitions, the model selection, and the pre-running of certain tools in Python before the agents see them, because not every LLM provider supports tool calling in the way the orchestration framework expects.
Three decisions worth naming.
Three decisions in the system are worth naming, because they generalise.
Specialist roles, not generalist agents. The standard pattern in multi-agent systems is to give each agent a slightly different system prompt and call them collaborators. The result is usually four versions of the same opinion. Architecture Council uses genuinely different roles, each defined by what it is responsible for, what tools it has access to, and what data it reads. The Standards Analyst sees the file tree and the linting output. The Enterprise Architect sees the import graph and the API surface. The Security Analyst sees the secret scanner results and the dependency manifest. They produce different findings because they are looking at different things, not because they have been told to disagree.
Different models for different perspectives. Perplexity is genuinely better at “what is the current state of this library in the wild” than the frontier reasoning models. Claude is genuinely better at “where are the coupling problems in this architecture”. GPT is genuinely better at “produce structured output that conforms to this schema”. Treating all LLMs as interchangeable is a mistake the industry made early and has been slow to unlearn. The Council uses different models because the alternative is worse output.
The synthesising chair. Four specialists produce four reports. They will sometimes disagree. The traditional weakness of multi-agent systems is that they reach consensus by averaging, which loses the structure of the disagreement. The Chair role exists to do what a good design authority chair does in person: read all four reports, identify where the specialists agree, identify where they diverge and why, and produce a single weighted ruling that names the disagreement rather than hiding it. The Chair also handles the case where the specialists are unanimously wrong, which happens, and which requires a model with the breadth to notice.
The system also pre-runs certain Python tools before the agents start, because Perplexity does not support function calling in the orchestration framework. The results are injected directly into the agent task descriptions. This is a workaround, not a feature, and the perspective worth taking from it is that the multi-LLM pattern often requires shimming around provider limitations in ways that any honest architecture diagram should name.
What changes when the friction is optional.
The interesting consequence of a sixty-second design authority panel is not that it replaces the board. It is that it makes authority review available at a different cadence.
A traditional design authority can review fifty significant decisions a year. That is the upper bound, set by meeting frequency and reading load. A sixty-second panel can review fifty thousand. That is not the same thing as a hundred-times-better authority. It is a different shape of authority. The board still exists. It now reviews the patterns the panel surfaces – the categories of finding that recur across hundreds of repositories, the architectural drift the panel detects week over week, the disagreements between specialists that the chair could not resolve. The panel does the volume. The board does the judgement.
This changes the operating model. In the current model, the board approves the big decisions and tolerates the small ones drifting in unsupervised directions. In the panel model, every decision worth recording gets a structured review on its way through. The board's role shifts from gatekeeper to pattern-recogniser. The board's product shifts from rulings to learning loops.
For a senior advisory practice, the question this raises in client engagements is not “should you build something like Architecture Council”. It is “what is the current friction cost of authority review in your organisation, and what would you do if it fell by three orders of magnitude”. The answer in most organisations is not “we would replace the board”. It is “we would change what we ask the board to do, because we would no longer need the board to do the thing the friction had forced upon them”.
That is a different shape of conversation than “should we adopt AI tools”.
What governance was actually for.
I want to be specific about what this perspective is and is not claiming.
It is not claiming that a multi-agent panel produces better architecture decisions than a human board. For genuinely novel, strategic, or politically charged decisions, a human board is the right answer and will remain so. The panel is a different tool for a different layer of decision: the volume layer, where the current friction means nothing gets reviewed at all.
It is not claiming that AI design authority is mature. The current state of LLM-based multi-agent systems is fragile in ways the Architecture Council prototype is honest about – tool-calling compatibility differs between providers, structured output reliability varies by model and by prompt, the cost of running four LLMs in parallel for every code review is non-trivial. Production deployment of this pattern in a regulated organisation needs care.
What it is claiming is that the operating model of design authority in most organisations was built around a friction cost that is now optional. That cost did real work – it forced organisations to be selective about what to review, which forced the board to focus on the big decisions. Removing the friction does not delete that work; it surfaces it as an explicit choice rather than an implicit constraint.
For practitioners thinking about AI governance in 2026, the useful question is not “how should we govern AI work”. The useful question is “what governance work has our organisation been outsourcing to friction, and what do we want to do now that the friction is going away”. That question is uncomfortable, because it forces governance leaders to articulate what their authority was actually for. It is also the right question.
The board has a future. The friction that defined the board's scope does not.
Architecture Council is available on GitHub under the MIT licence. It is a working prototype, not a supported product. The thinking behind it, and the implications for design authority practice in regulated organisations, is what this perspective is really about.